Early Start
Consensus Protocols can be daunting to understand, especially when there are so many variants of consensus protocols like Paxos, RAFT, PBFT, shoot View stamped replication etc. Although a deep theoretical understanding is needed to understand the mechanism of these protocols, I believe a cursory understanding of these protocols is necessary to build tooling related to databases. In turn, we need tools that can visualize consensus, allow for developers to visualize and see the code executed in the consensus path - all of this while the code is being executed. Not only this, but we need our tools to be a sidecar, be non intrusive and scale on logic and event capturing details without affecting the source. See how a combination of eBPF, AI and MCP servers enable creating some really cool tooling.
Background
So in a context of distributed systems, there are many replicas or nodes which are involved together to form a cohesive system. When a request flows into a distributed database, it usually goes to the leader node, which then sends it other replicas - these replicas agree on this new value and then commit it to their local state. Thus this idea of agreeing on a client request or reaching "consensus" is done by a class of protocols called consensus protocols. Now I am no expert in this, but these guys are (I am part of it, so why not me too) - Expolabs. Consensus protocols can be broadly classified as crash and fault tolerant. Crash tolerant protocols like Paxos and RAFT tolerate crash of replicas, so if 1 replica goes down, how will the consensus process be affected? If the leader goes down, then who will be the next leader? Think you classic distributed databases - MongoDB, TiDB run some flavor of Paxos / RAFT. Fault tolerant protocols are interesting, they can tolerate faults or byzantine (might be named after the empire, dont quote me on it) behaviour. These are essentially not only is a replica faulty but it could be malicious, so a participating node could send out false signals and messages. Think Blockchain, a lot of cool databases like Apache ResilientDB, Tendermint, Hyperledger run some form of PBFT (the PAXOS of fault tolerant protocols).
Problem Statement
I want to visualize consensus—not a simulation. It would be very cool if my Prometheus or Grafana tool suite had a database explorer tab where I could visualize the consensus process for every request coming in. Second, agnostic of the database, can I visualize the code being executed for consensus and other operations? Maybe I can use this to optimize or just explore the codebase.
Lets Cook
I really don't have a better subheading honestly. So let's tackle this problem and identify what technology we could leverage. We had a separate consensus visualizer already made by some cool folks at Expolabs - Check this article by Aunsh ResView. The existing implementation used custom code to track requests and capture timestamps for each request. I had an idea - "Well I wonder if we could use eBPF here? Can we just offload this to a sidecar, that way I can capture other sub-protocols, like maybe add support for view change, checkpointing later, make it extensible while also only enabling it when needed".
This was the spark plug - eBPF. eBPF stands for extended Berkeley Packet Filter and lets you run sandboxed user-defined code in the kernel without modifying kernel code. People write Linux schedulers, observability tools using eBPF—it's very powerful. For our use case, eBPF's ability to attach probes to userspace functions makes it perfect for building a non-intrusive consensus visualization sidecar.
Firstly, Consensus visualizer
Lets make the problem simple, consider a single replica where - for a specific request when function A is called, we would want to capture some details (like time, stage etc), similarly for function B, function C etc. Then we could use this temporal log and recreate the consensus graph for a particular request. Thus this data is at a per request level and thus very granular. This also means our code will be called in the hot path and thus needs to be blazingly fast.
Before diving into the details, this is what we build: an eBPF-based consensus visualizer. Demo: ResView eBPF.
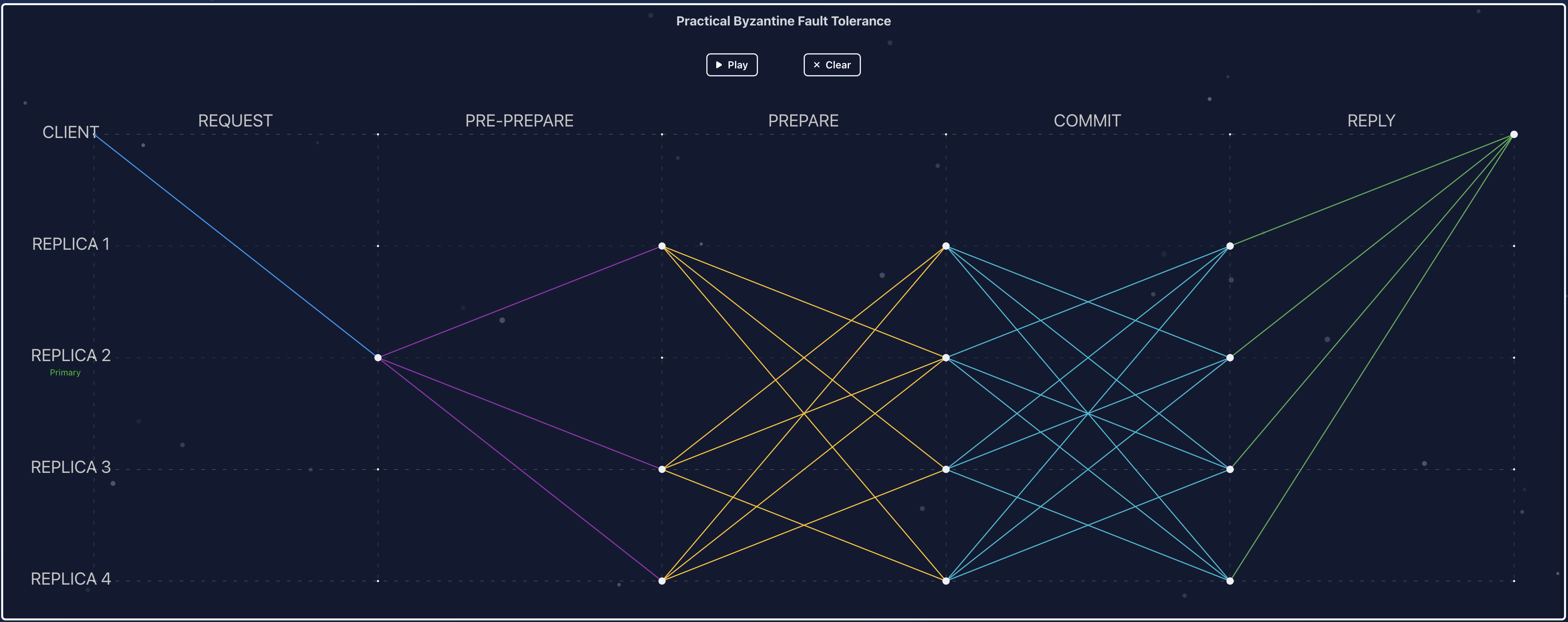
eBPF-based consensus visualizer — Looking at the screen, we need tracepoints at key consensus functions—PRE-PREPARE, PREPARE, COMMIT, etc. For a request with a specific sequence number (think of it as a unique request ID), we can track these functions for a specific replica and capture consensus details from that replica's perspective to recreate the graph.
How do we get notified when these functions are called? This is where eBPF comes in. We can define USDT (User Statically-Defined Tracing) probes at these consensus functions, which generate events when executed. eBPF programs attach to these probes to capture the execution flow. The best part: when probes aren't attached, they compile down to NOP instructions with essentially zero overhead—the consensus code runs normally, but the tracing instrumentation costs nothing when disabled.
USDT probes are compiled directly into the application binary. Projects like PostgreSQL do this by defining probes in a .d file (like probes.d) and compiling with --enable-dtrace. The dtrace compiler generates object files that get linked into the binary, embedding probe metadata in ELF notes. When you add DTRACE_PROBE() macros in your code (or use provider-specific macros), they compile to NOP instructions that can be dynamically replaced with breakpoints when tracing is enabled.
When you run your program using gdb for example, tools like dtrace etc work similar to this in idea. So we are essentially building some sort of debugger.
For our consensus implementation, we can add user-defined probes directly in the source code using USDT macros. Of course, the invocation could be guarded by a macro to make it optional at compile time. Ideally we can capture this data without any source code changes, but since this consensus implementation is in C++, the function names we're targeting are often mangled, making it harder to attach probes dynamically.
So this is how the hook looks like - our lightweight event dispatcher
extern "C" {
__attribute__((noinline)) void resdb_trace_consensus_commit(
uint64_t req_ptr, uint64_t seq, uint32_t type, uint32_t sender_id,
uint64_t proxy_id) {
asm volatile("" : : "r"(req_ptr), "r"(seq), "r"(type), "r"(sender_id),
"r"(proxy_id)
: "memory");
}
....
}This is how this would be integrated into the function which we want to track
int ConsensusManagerPBFT::ConsensusCommit(std::unique_ptr<Context> context,
std::unique_ptr<Request> request) {
resdb_trace_consensus_commit(
reinterpret_cast<uint64_t>(request.get()), request->seq(),
static_cast<uint32_t>(request->type()),
static_cast<uint32_t>(request->sender_id()), request->proxy_id()); // <--- We add our event dispathcer here
LOG(INFO) << "recv impl type:" << request->type() << " "
<< "sender id:" << request->sender_id()
<< " primary:" << system_info_->GetPrimaryId();
// If it is in viewchange, push the request to the queue
// for the requests from the new view which come before
// the local new view done.
recovery_->AddRequest(context.get(), request.get());
...
}Thus now when ConsensusCommit is called, then we can associate this invocation to the request metadata and ultimately are able to track a single request.
So now that we have something dispatching these events, how do we capture and consume them? There are many tools and languages to define eBPF programs, including C and custom DSLs like bpftrace. Here's how our bpftrace script looks:
uprobe:/home/ubuntu/production/incubator-resilientdb/bazel-bin/service/kv/kv_service:resdb_trace_pbft_request
{
// args: req_ptr, seq, meta, proxy_id, epoch_ns
$meta = arg2;
$type = $meta & 0xffffffff;
$sender = ($meta >> 32) & 0xffff;
$self = ($meta >> 48) & 0xffff;
printf("%llu %lld %d %d request %lu sender=%u self=%u proxy=%lu req=0x%lx type=%u\n",
nsecs, arg4, pid, tid, arg1, $sender, $self, arg3, arg0, $type);
}
uprobe:/home/ubuntu/production/incubator-resilientdb/bazel-bin/service/kv/kv_service:resdb_trace_pbft_pre_prepare
{
$meta = arg2;
$type = $meta & 0xffffffff;
$sender = ($meta >> 32) & 0xffff;
$self = ($meta >> 48) & 0xffff;
printf("%llu %lld %d %d pre_prepare %lu sender=%u self=%u proxy=%lu req=0x%lx type=%u\n",
nsecs, arg4, pid, tid, arg1, $sender, $self, arg3, arg0, $type);
}This bpftrace script attaches uprobes to the consensus functions (resdb_trace_pbft_request and resdb_trace_pbft_pre_prepare). When these functions are called, the script extracts metadata from arg2 using bitwise operations—unpacking the message type, sender ID, and self ID from a packed 64-bit value. It then prints structured output with timestamps (nsecs, arg4), process/thread IDs (pid, tid), sequence number (arg1), and the extracted metadata. This creates a trace log that we can use to reconstruct the consensus flow.
Awesome, that's a lot to take in, I know. But the core idea here is how we can use eBPF as a powerful tool to build these extensible event-based systems. It's really interesting to think about—the mechanism is basically like a debugger where breakpoints are these hook functions or uprobes we define. Pretty wild right?
Age of AI
Now that we have a nice tool, let's put a bow on it—using some AI. The best way to expose our consensus visualization tool is through an MCP (Model Context Protocol) server. MCP lets AI assistants interact with external tools and resources, and with MCP UI resources, we can embed interactive visualizations directly in the chat interface. It's pretty neat honestly.
Here's how we define a tool that exposes our consensus visualizer:
@mcp.tool
def trace_request(request_id: str = "", enable_data_table: bool = False, enable_commit_graphs: bool = False) -> ToolResult:
"""Trace a request across the PBFT consensus layer.
This tool displays a UI resource that allows you to trace a request
through the PBFT consensus layer using the ResilientDB visualizer.
Args:
request_id: Optional request ID to filter the trace view.
If not provided, shows the general visualizer.
enable_data_table: If True, enables the data table view (dataTable=true).
enable_commit_graphs: If True, enables the commit graphs view (mvt=true).
Returns:
ToolResult with a UI resource containing the trace visualizer
Example:
trace_request(request_id="tx_12345", enable_data_table=True)
"""
try:
visualizer_url = "https://dev-res-view.vercel.app/pages/visualizer"
params = []
if request_id:
params.append(f"seq={request_id}")
if enable_data_table:
params.append("dataTable=true")
if enable_commit_graphs:
params.append("mvt=true")
if params:
visualizer_url = f"{visualizer_url}?{'&'.join(params)}"
resource_uri = "ui://res_view/visualizer"
ui_resource = {
"type": "resource",
"resource": {
"uri": resource_uri,
"mimeType": "text/uri-list",
"text": visualizer_url,
},
}
summary = "Opening trace visualizer to view request flow through PBFT consensus layer."
if request_id:
summary += f" Filtering for request ID: {request_id}"
if enable_data_table:
summary += " Data table view enabled."
if enable_commit_graphs:
summary += " Commit graphs view enabled."
return ToolResult(
content=[
TextContent(type="text", text=summary),
ui_resource,
],
structured_content={
"success": True,
"resource_uri": visualizer_url,
"visualizer_url": resource_uri,
"request_id": request_id,
"enable_data_table": enable_data_table,
"enable_commit_graphs": enable_commit_graphs,
},
)
except Exception as e:
error_msg = str(e)
return ToolResult(
content=[TextContent(type="text", text=f"Error creating trace visualizer: {error_msg}")],
structured_content={
"success": False,
"error": error_msg,
},
)MCP UI resources let you embed interactive visualizations directly in AI chat interfaces. When an AI assistant calls trace_request(), it returns a UI resource that the client can render—in this case, our consensus visualizer. You can ask the AI to "trace request 1151" and it'll open the visualizer filtered to that specific request, or enable data tables and commit graphs for deeper analysis. It's like having a debugger interface accessible through natural language. Pretty cool right?
The MCP server code is available here: DeepObserve, and the eBPF hooks for ResilientDB are in the demo-final branch. Check out a demo of this in action here. Honestly, seeing consensus flow visualized in real time through an AI chat interface is admittedly a very cool experience. I know grafana did some very cool AI stuff, but doing it yourself makes it even that much better.
Conclusion
So here's the thing—we built an eBPF-based consensus visualizer that lets you peek into consensus execution in real time. No source code changes, no recompilation, just attach some probes and boom, you're watching your consensus protocol do its thing. Pretty wild right?
The way I see it, we're basically building a debugger for production systems. Except instead of stepping through code line by line, you're capturing events at scale, visualizing them, and then asking an AI to make sense of it all through natural language. I know that sounds a bit sci-fi, but honestly, it works. And the best part? It's non-intrusive. Your consensus code runs at full speed, and the tracing overhead is basically zero when you're not actively probing. There are some very cool optimizations when it does run like using a userspace BPF runtime do reduce the number of userspace to kernel jumps. These guys are great, you should check them out - eunomia
Next week, we're diving into flamegraphs—using eBPF to visualize where your code actually spends its time. Same toolkit, different angle. Instead of "what's happening in consensus?", we're asking "where is my code burning CPU?". Till next time!