My first task as an intern was to design this really crisp dashboard for an order management system which involved a gnarly SQL query. The query had a gazillion joins, we sadly used an ORM at that time, life was interesting to say the least. Later, I decided to go back to school (again), I had taken a compilers course and had to come up with a project.
So I thought to myself - "What if I could take that massive SQL statement and break it down into subcommands - kinda like piping them together? If you really think about it a LIKE statement in SQL is kinda sorta like grep, and I could model mongo queries using tools like jq, ooh and what if I could query all databases using a single language?" My mind was racing with these questions, and tbh even though these might be slight oversimplifications, I really liked the thought of it.
Early Start
I was really interested in writing the frontend of a compiler, having built a few interpreters for example - lox a toy languages, I felt I could port over this experience into a meaningful project for my compilers course. Now mind you, most of my projects were tools related, like adding some contextual hints to a repository for an LSP etc. I did not know much about how the intermediate AST actually runs - Well I knew it in theory, but I never got to making a virtual machine bytecode interpreter or something in that realm. Maybe the closest I came to was building an interpreter for lox, my toy language but thats about it. That being said, I actually like databases, and I wanted to do something which is databases but just enough compilers to get a good grade. So I went to my professor and sure enough I was introduced to the world of LLVM. I was intrigued.
Query Engines
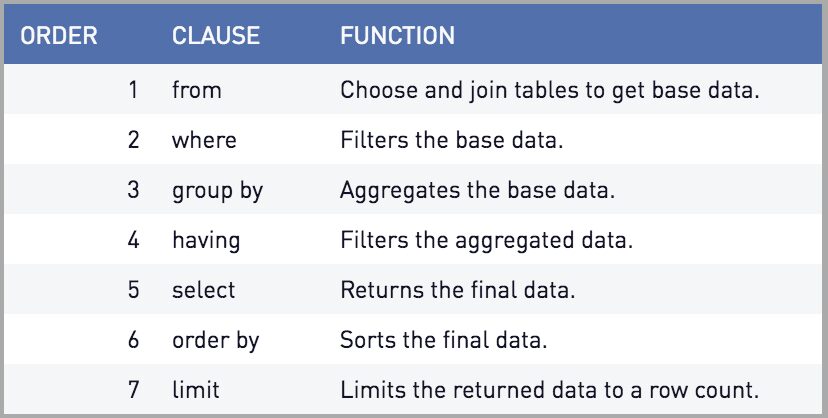
So before moving to LLVM, let's briefly talk about query engines. As a total beginner to this area, this is what my understanding is. Again I want to preface this by saying that this is just my understanding as all things are, so alright. Databases usually have an interface to interact with, either pulling data from it or adding/modifying data to it. So in relational databases, SQL is the de facto, right - your DDL (Data Definition Language) and DML (Data Manipulation Language). In MongoDB for example, you use MongoDB's query language - with totally easy to use nested statements, which are extremely easy 😉 to debug (not ruling out skill issue. I did this before AI so not so much now). InfluxDB uses the Flux language, Cassandra uses, I believe, CQL and a bunch of other query languages, SQL being the head of the snake. Well the core idea is that this query gets turned into a sequence of operators and the database query engine executes and produces a stream of tuples. Think of the query engine as a compiler, right? So this becomes the "frontend" of the query engine, it gets turned into either an AST, for an interpreter (like python) or gets compiled down to bytecode (like java) or to a C program or some intermediate representation. The "backend" then goes ahead and executes it right - takes care of the in-memory processing, or maybe spill some to the disk etc. Most databases do the interpreter approach where they convert the query into an AST (Abstract Syntax Tree) and then run a tree walking interpreter over it and then execute it. Remember the order in which SQL executes.
So this is a class of interpreted query engines, there are some neat optimizations which can be done here like processing a batch of tuples at once - also called vectorized engines. DuckDB is a great example of this, and Postgres and MySQL have some vectorized operations too. There is a different class of databases which do code generation - which is turn the user query into an intermediate representation into an executable code or just query directly to code. This then gets executed right. So examples of this are Hyper, ClickHouse, Apache Spark (with whole-stage code generation). Here is a blog post which covers this topic in great detail - Database Execution Engines. Phil is great, you should read more of his blogs. Alright, so tree walking is trivial (not really, but my professor told me this project needs to be novel). So lets focus on codegen - Is there a compiler framework which provides us with tools to define an intermediate representation and maybe generate some C++ code given the IR. LLVM is the perfect fit here.
LLVM
Alright, so we looked at how we got here right - a user defined query into some IR and then we execute this. This although begs a question - Why do we need an IR? Isnt this just adding an extra step to our hot path so to speak? Can we just take the query and execute it directly? I had these questions and I will attempt to answer them.
Let's take a SQL statement right - every SQL query requires creating a query plan. The challenge is finding the most optimal way to order predicates, push them down to the data source, and choose the most optimal query plan to execute. Think about it - you could have a query with multiple joins, filters, and aggregations. The order in which you execute these operations matters a lot for performance. Should you filter first before joining? Should you push down predicates to reduce the data early? These are all optimization decisions that need to be made.
The IR gives us a structured representation of the query plan that we can analyze, transform, and optimize before we generate executable code. Without an IR, we'd have to make all these optimization decisions upfront when parsing the SQL, which is messy and inflexible. With an IR, we can apply multiple optimization passes - predicate pushdown, join reordering, constant folding, dead code elimination - all before we generate the final executable code. So yeah, the IR might add an extra step, but it's what enables us to generate truly optimized query execution code.
And if you think about it, having a common IR makes targeting different execution backends easier - we can have a single declarative interface that compiles down to an IR, which can then be lowered to different execution targets (like CPU, GPU, or different query engine backends). New Term Alert MLIR or Multi-Level Intermediate Representation is a standardized framework for defining various IRs that can be progressively lowered through different abstraction levels. These lowerings transform the IR from higher-level to lower-level representations, and optimization passes can be applied at each stage along the way. And they are part of the LLVM ecosystem.
Let's Cook
Our professor tells us that the best way to start a project is to fork somebody else's project. I however did not do this because I had too much of a "let me cook" attitude. First it took me a minute (2 days to be exact) to download the latest LLVM version, compile the MLIR tools with debug information and all that fun stuff. Nothing more in this world, I like to do than fighting CMake. Alright now that we have the "backend" tools we need a language right, we need YAQL - yet another query language. Well, Jeff Shute and the folks at Google had this paper, which was essentially SQL but engineered towards more modern use cases - ease of use, autocompletions etc. Around the same time Databricks and Snowflake had implemented similar ideas, so I was sure this was a pretty decent thing to do.
While LLVM was compiling, I coded up a tree walking version of my query language PipeQL over a simple JSON file. So now the next step was MLIR, tbh we have a 10 week quarter and just formulating a problem statement took me like 3-4 weeks. As much as I wanted to learn MLIR through tutorials, I wish I had the luxury of time, plus I was doing a gazillion things at once during this time. So we go back the faithful forking. Thats when I found out Substrate and LingoDB.
Implementation
LingoDB honestly was the closest project which was doing what I exactly wanted to do. Please do check out their page and give their white paper a read, it is really good. They have an open source implementation of their work which is perfect. In the short time I had, my goal was simple, lets come up with the definition for PipeQL i.e actually defining the language and the keywords and change LingoDB's SQL -> MLIR path to PipeQL -> MLIR. This was sort of the path of least resistance and I knew I could get a subset of SQL ported over to PipeQL. I really liked to focus on SELECT queries, so thats what we will implement.
Grammar
So defining a parser is kind of very very easy. It's essentially defining a grammar ( yes all your LL, LR parsers) and then using a tool like Antlr to create a parser class for it. Antlr uses the visitor pattern, and once a grammar is defined, Antlr provides you with a nice Visitor class for it.
grammar PipeQL;
// Entry point for the query
query
: fromClause pipeOperator* EOF
;
// FROM clause
fromClause
: FROM IDENTIFIER (aliasClause)?
;
// Pipe operators
pipeOperator
: PIPE_OPERATOR selectOperator
| PIPE_OPERATOR whereOperator
| PIPE_OPERATOR orderByOperator
| PIPE_OPERATOR unionOperator
| PIPE_OPERATOR intersectOperator
| PIPE_OPERATOR exceptOperator
| PIPE_OPERATOR assertOperator
| PIPE_OPERATOR limitClause
;
// SELECT pipe operator
selectOperator
: SELECT selectExpression (',' selectExpression)*
;
// WHERE pipe operator
whereOperator
: WHERE booleanExpression
;So this is what the language grammar looks like, so this allows you to define queries like so -
FROM users |> SELECT *
FROM users |> SELECT name, age, email
FROM users |> SELECT * |> WHERE age > 18
Kinda cool if you ask me right, and its pretty easy to do, define the grammar and you can get a parser class up and running pretty quick. Now lets jump into the intermediate representations of these. We don't actually change the definition of the IR itself the way it is defined i.e the algebra, the operators etc, but just the interface in PipeQL from the original SQL implementation. They use the parser from postgres, which thinking about it should be a blog in itself.
MLIR
Let's use this statement to analyze the MLIR code and actually break down the IR. The below statement generates something like this in LingoDB's MLIR dialect. This is the high level IR, before any lowering - think of it as the top level representation.
- FROM users |> SELECT * |> WHERE age > 18
module {
func.func @main() {
%0 = relalg.query (){
%1 = relalg.basetable {table_identifier = "users"} columns: {age => @users::@age({type = !db.nullable<i32>}), email => @users::@email({type = !db.nullable<!db.string>}), id => @users::@id({type = !db.nullable<i32>}), name => @users::@name({type = !db.string})}
%2 = relalg.selection %1 (%arg0: !tuples.tuple){
%4 = tuples.getcol %arg0 @users::@age : !db.nullable<i32>
%5 = db.constant(18 : i32) : i32
%6 = db.compare gt %4 : !db.nullable<i32>, %5 : i32
tuples.return %6 : !db.nullable<i1>
}
%3 = relalg.materialize %2 [@users::@id,@users::@name,@users::@age,@users::@email] => ["id", "name", "age", "email"] : !subop.local_table<[id$0 : !db.nullable<i32>, name$0 : !db.string, age$0 : !db.nullable<i32>, email$0 : !db.nullable<!db.string>], ["id", "name", "age", "email"]>
relalg.query_return %3 : !subop.local_table<[id$0 : !db.nullable<i32>, name$0 : !db.string, age$0 : !db.nullable<i32>, email$0 : !db.nullable<!db.string>], ["id", "name", "age", "email"]>
} -> !subop.local_table<[id$0 : !db.nullable<i32>, name$0 : !db.string, age$0 : !db.nullable<i32>, email$0 : !db.nullable<!db.string>], ["id", "name", "age", "email"]>
subop.set_result 0 %0 : !subop.local_table<[id$0 : !db.nullable<i32>, name$0 : !db.string, age$0 : !db.nullable<i32>, email$0 : !db.nullable<!db.string>], ["id", "name", "age", "email"]>
return
}
}So this is very interesting to look at right because we see some elements from our query in here. We see our table name users, the columns queried and their types. Then we see the predicate involving the WHERE clause in the form of a small lambda function so to speak. Sidebar - These would be so cool for UDF's right.
We have some other components here and then we yield control back. So kind of like converting a PipeQL or a SQL query into a function automatically right.
Maybe to go into some nerdy details about IR and compilers, LLVM IR like MLIR needs to be written in SSA where each variable is assigned a value exactly once, simplifying powerful optimizations like constant propagation and dead code elimination, making code faster and analysis easier. So if the WHERE clause was something like age > (10 + 8) then we could do constant folding and other optimizations compilers do.
So in essence all we did was define a language, a grammar for it and then integrate that into the LingoDB framework so that when the visitor class sees a WHERE clause, it knows the specific IR primitive to be called. So its very much like Query -> AST -> IR -> IR1 -> IR2 ...... -> Executing Generated Code.
Wrapping Up
I actually had a ton of fun doing all of this, researching and implementing this. You can find my work here - PipeQL and my in class presentation here. As much as I would have liked to do some more stuff like having the full SQL feature set in PipeQL and have some utilities to define UDF's maybe. I would classify this as more of a exploratory project idea which can inspire some cool ideas. I would love some collaborators and continue this work. Hope this was something new and fun and till next time.